06.07.2018 07:56:18
Europarlament ei kiitnud vastuolulist autorikaitse eelnõu heaks, Tunne Kelam hääletas poolt
Euroopa Parlament lükkas neljapäeval tagasi vastuolulise autorikaitseseaduse eelnõu selle praegusel kujul, jätkates küsimuse arutamist septembris.
Hääletusel olid direktiivi vastu 318 ja poolt 278 saadikut, erapooletuks jäi 31.
Seaduse eesmärgiks on tagada internetis sisutootjatele õiglane autoritasu, kuid ettepanekut laitsid häälekalt nii USA tehnoloogiahiiud kui ka internetivabaduse aktivistid, kelle hinnangul tähendanuks selle heakskiitmine olulisi piiranguid sõnavabadusele.
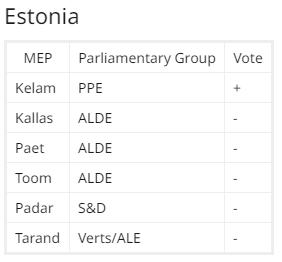
Eesti saadikutest hääletas ainsana eelnõu poolt Tunne Kelam.
Osiris, kahtlen sügavalt, et ta suudab aduda, et selle eelnõu vastuvõtmisel võib põhimõtteliselt kõik Euroopa online kommuunid sulgeda või pankrotti ajada.
Kaja Kallas, eile Vikerraadios - oli vist Uudis+, ütles umbes sedamoodi:
"Selle supersuure lobitöö taga on Saksamaa ning Prantsusmaa hiilgesuured firmad. Ning kes selliselt siis väiksemad ära kaotavad ja siis turu endale haaravad".
PS: Selles pole midagi erilist tegelikult. Meediamaastik viimastel aastatel on olnud nagunii "suurte meediasõdada tallermaa" ning kus käib pidev väiksemate kokkuostmine.
Muuseas, selle eelnõu autor on europarlamendi saadik Tarandi jutu järgi ACTA-aegadest tuntud seemne- ja fooliumimees eurovolinik ANSIP ise. _________________ Otsin veebiprogejat (kuulutuste portaal)
5. juuli Äripäeva raadio hommikuprogrammis oli arutelu Eesti vikipeedia juhiga ning ta mainis ka, et Ansipi käsi on mängus kogu selles asjas. _________________ The sh*t has hit the fan.
5. juuli Äripäeva raadio hommikuprogrammis oli arutelu Eesti vikipeedia juhiga ning ta mainis ka, et Ansipi käsi on mängus kogu selles asjas.
Siis vanad ACTA tüübid hoos
Vaadake, et "valesüüdistuse eest kohtu alla ei anta".
Wikipedia ise väidab selgelt ning üheselt, et see kõik sai alguse kaua aega tagasi ning nagu Wikipedia välja toob - leiab tol ajal hoopis Siim Kallase nime...
European Union lobbying
From Wikipedia, the free encyclopedia
Naiivne küsimus - aga kuskohast te küll võtate need sajad tuhanded või miljonid programmeerijad kes suudavad programmerida triljoneid ridu (Algoritmide) koode.
Kasvõi kui seda vaadates kuidas kirjandusest on tegelikult digiteeritud üsna väike osa. Ülejäänud osa tuleb ikkagi käia raamatukogudes lugemas.
See saab väga huvitav vaatepilt olema kui kümned tuhanded programmeerijad on raamatukogudes, et siis raamatud-ajalehed ükshaaval, rida realt arvutitesse trükkida ning Algoritmidesse programmeerida.
---------------------
Ja veel - kellel on käepärast tänane Paber-Postimees, siis seal on ühe härrasmehe poolt pikem lugu ning paistab sedamoodi, et seda härrat ikka väga huvitab, et kõik tema mõtted "on luku taga ja kes neid teada tahab, peab selle eest maksma".
Naiivne küsimus - aga kuskohast te küll võtate need sajad tuhanded või miljonid programmeerijad kes suudavad programmerida triljoneid ridu (Algoritmide) koode.
Youtube on selle asja jaoks juba kirjutanud "Content ID" nimelise algoritmi, ja neil on üldse kokku u. tuhat töötajat, kellest suurem osa on ilmselt kasutajatugi.
Seega triljon rida koodi on tõenäoliselt liiga palju sellise algoritmi jaoks. Ilmselt piisaks ka sajast programmeerijast ja miljonist reast.
tahanteada kirjutas:
Kasvõi kui seda vaadates kuidas kirjandusest on tegelikult digiteeritud üsna väike osa. Ülejäänud osa tuleb ikkagi käia raamatukogudes lugemas.
See saab väga huvitav vaatepilt olema kui kümned tuhanded programmeerijad on raamatukogudes, et siis raamatud-ajalehed ükshaaval, rida realt arvutitesse trükkida ning Algoritmidesse programmeerida.
Programmeerijad ei hakkaks kohe kindlasti raamatuid arvutisse trükkima. Nemad peaksid kirjutama vaid algoritmi, mis suudab kontrollida suvalist teksti/pilti/heli.
Andmeid hakkaksid sisestama hoopis teised inimesed, kes peavad vaid oskama lugeda ja arvutil kirjutada, ning kellele saab seetõttu palju vähem palka maksta kui programmeerijatele.
Teiseks, ilma autori nõusolekuta tema teoste digiteerimine oleks samuti autoriõiguste rikkumine.
Nii et kõik, kes tahaksid, et nende autoriõigusi kaitstaks, peaksid kõigepealt ikkagi ise selle eest hoolt kandma, et nende teosed oleksid digitaalsel kujul kontrollitavad.
viimati muutis julmu 07.07.2018 11:49:10, muudetud 1 kord
Naiivne küsimus - aga kuskohast te küll võtate need sajad tuhanded või miljonid programmeerijad kes suudavad programmerida triljoneid ridu (Algoritmide) koode.
Youtube on selle asja jaoks juba kirjutanud "Content ID" nimelise algoritmi, ja neil on üldse kokku u. tuhat töötajat, kellest suurem osa on ilmselt kasutajatugi.
Seega triljon rida koodi on tõenäoliselt liiga palju sellise algoritmi jaoks. Ilmselt piisaks ka sajast programmeerijast ja miljonist reast.
tahanteada kirjutas:
Kasvõi kui seda vaadates kuidas kirjandusest on tegelikult digiteeritud üsna väike osa. Ülejäänud osa tuleb ikkagi käia raamatukogudes lugemas.
See saab väga huvitav vaatepilt olema kui kümned tuhanded programmeerijad on raamatukogudes, et siis raamatud-ajalehed ükshaaval, rida realt arvutitesse trükkida ning Algoritmidesse programmeerida.
Programmeerijaid ei hakkaks kohe kindlasti raamatuid arvutisse trükkima. Nemad peaksid kirjutama vaid algoritmi, mis suudab kontrollida suvalist teksti/pilti/heli.
Andmeid hakkaksid sisestama hoopis teised inimesed, kes peavad vaid oskama lugeda ja arvutil kirjutada, ning kellele saab seetõttu palju vähem palka maksta kui programmeerijatele.
Teiseks, ilma autori nõusolekuta tema teoste digiteerimine oleks samuti autoriõiguste rikkumine.
Nii et kõik, kes tahaksid, et nende autoriõigusi kaitstaks, peaksid kõigepealt ikkagi ise selle eest hoolt kandma, et nende teosed oleksid digitaalsel kujul kontrollitavad.
Ära unista - isegi mõne vähe paksema raamatu analüüsi jaoks on sul vaja miljardeid koodiridu.
Seda lihsalt põhjusel, et see paks raamat võib sisaldada tuhandeid erinevaid sõnu ning need sõnad võivad veel asuda tuhandetes erinevates lauseversioonides.
Ja nüüd see õnnetu programmerija peab sinna Algortimi sisestama kõik need sõnad ja kõik need lauseversioonid. Ilma selleta ei oska see Algoritm midagi kontrollida.
See pole minu väljamõeldis Mingi aeg tagasi oli - vist Vikerraadios - intervjuu ühe Eesti keele "programmeerimise" teema "juhtiva jõuga" (nimi pole kahuks meeles),
siis tema kurtis kahte asja:
1. Eesti keele viimisega arvutisse alustati Tartu Ülikoolis eelmise aasta 1960-tel aastatel.
Kuid siiamaani pole selle projektiga veel hakkama saadud.
2. Ning uuema probleemiga, igapäevaselt, maadeldakse justnimelt sellega, et koodiridade arv on aastatega ülisuureks kasvanud ning mitte keegi enam ei suuda tegelikult seda koodimassi ei hallata ega kontrollida.
3. Ning seetõttu tegeldakse sellise asjaga nagu "koodide optimeerimine", ehk siis selline tegevus kus otsitakse lahendusi kuidas sama koodi saaks kirjutata väiksema koodiridade arvuga.
PS: Mis aga puutub raamatuteksti arvutisse kirjutamisse, siis seda peab tegema justnimelt programmeerija. Sest siis, koos selle sisestamisega, saab ta selle raamatu läbi lugeda ning siis ta teab mida see Algoritm selle konkreetse teksti korral otsima peab.
Kui programmeerija pole lugenud raamatut "Sõda ja rau", siis ei oska ta ka tegelikut Algoritmi kirjutada kuna ta ei tea kes on Nataša ning mida ta ütelnud on või mida teinud.
Ma olen varasemalt paar raamatut - lugemiseks ning pimekirja harjutamiseks - arvutisse trükkinud. Ja selle käigus oligi nii, et samal ajal lugesin ka raamatud läbi. Kusagil a 1000 lehekülge trükkimist.
Ära unista - isegi mõne vähe paksema raamatu analüüsi jaoks on sul vaja miljardeid koodiridu.
Seda lihsalt põhjusel, et see paks raamat võib sisaldada tuhandeid erinevaid sõnu ning need sõnad võivad veel asuda tuhandetes erinevates lauseversioonides.
Ja nüüd see õnnetu programmerija peab sinna Algortimi sisestama kõik need sõnad ja kõik need lauseversioonid. Ilma selleta ei oska see Algoritm midagi kontrollida.
"Sõda ja rahu" on üks paksemaid raamatuid maailmas ja seal on "ainult" pool miljonit sõna - milleks oleks vaja iga sõna kohta veel mitutuhat rida koodi kirjutada?
Eesmärgiks on siiski vaid kontroll, et keegi autoriõigustega kaitstud materjali ei kopeeriks, mitte panna arvutit kirjandusest aru saama.
Muidu polekski võimalik enam ühtegi raamatut kirjutada, kuna igas raamatus kasutatakse sõnu ja teemasid, mida juba mõnes varasemas raamatus on kasutatud.
tahanteada kirjutas:
See pole minu väljamõeldis Mingi aeg tagasi oli - vist Vikerraadios - intervjuu ühe Eesti keele "programmeerimise" teema "juhtiva jõuga" (nimi pole kahuks meeles),
siis tema kurtis kahte asja:
1. Eesti keele viimisega arvutisse alustati Tartu Ülikoolis eelmise aasta 1960-tel aastatel.
Kuid siiamaani pole selle projektiga veel hakkama saadud.
2. Ning uuema probleemiga, igapäevaselt, maadeldakse justnimelt sellega, et koodiridade arv on aastatega ülisuureks kasvanud ning mitte keegi enam ei suuda tegelikult seda koodimassi ei hallata ega kontrollida.
3. Ning seetõttu tegeldakse sellise asjaga nagu "koodide optimeerimine", ehk siis selline tegevus kus otsitakse lahendusi kuidas sama koodi saaks kirjutata väiksema koodiridade arvuga.
Ma ei tea küll, mis nende eesmärk on, aga ma arvan, et see on midagi auahnemat kui lihtsalt autoriõiguste kontroll.
Kunagi 1960. aastatel eesti keele filoloogide poolt kirjutatud kood on tänapäevaste programmeerimis-standardite järgi väärtusetu, kuna tarkvaratehnika on viimase 50 aasta jooksul tohutult arenenud.
Koodi optimeerimine on minu meelest tänapäeval iseenesest mõistetav asi, mida peaks iga programmeerija oskama ja igapäevaselt tegema.
Kui olemasolevas algoritmis seda tehtud pole, siis võib-olla nende probleem ongi selles, et keegi ei julge seda vana koodi minema visata ja nullist alustada, kuna paljud austusväärsed professorid on sellega aastakümnete jooksul vaeva näinud.
tahanteada kirjutas:
PS: Mis aga puutub raamatuteksti arvutisse kirjutamisse, siis seda peab tegema justnimelt programmeerija. Sest siis, koos selle sisestamisega, saab ta selle raamatu läbi lugeda ning siis ta teab mida see Algoritm selle konkreetse teksti korral otsima peab.
Kui programmeerija pole lugenud raamatut "Sõda ja rau", siis ei oska ta ka tegelikut Algoritmi kirjutada kuna ta ei tea kes on Nataša ning mida ta ütelnud on või mida teinud.
Kui iga raamatu jaoks tuleks uus algoritm kirjutada, siis on see üks kehv algoritm. Programmeerija peaks pärast mõne raamatu läbilugemist suutma kirjutada algoritmi, mis sobib kõikide raamatute jaoks.
Kui ta seda ei suuda, siis ta on kehv programmeerija ja peaks mingit muud tööd tegema.
Ära unista - isegi mõne vähe paksema raamatu analüüsi jaoks on sul vaja miljardeid koodiridu.
Seda lihsalt põhjusel, et see paks raamat võib sisaldada tuhandeid erinevaid sõnu ning need sõnad võivad veel asuda tuhandetes erinevates lauseversioonides.
Midagi nii.. hm, ebaadekvaatset.. pole minu silmad juba ammu lugenud.
Sul ei ole õrna aimugi, mis on "algoritm". Ja sul pole poole penni jagugi teadmisi programmeerimisest.
Esiteks, mitte kunagi ei hardkoodita programmi sisse mingeid sõnu, mida hiljem analüüsitakse. See on "data" mille programm loeb sisse andmebaasidest. Või mis iganes muul moel. Igatahes ei pea programmeerija nendest sõnadest midagi teadma.
Teiseks, tegelikult ei pea programmeerija isegi teadma, kuidas algoritm töötab. Tema asi on sellest matemaatiliselt aru saada ja see siis programmeerimiskeeles implementeerida. Suuremates programeerimisfirmades ei ole isegi programmeerijad need, kes algoritme välja töötavad. Algoritmid on sageli väga valdkonnaspetsiifilised ja nende väljatöötamisega tegelevad oma ala spetsialistid ja teadlased.
Ühesõnaga - ära targuta teemadel, millest sul õrna aimugi pole.
P.S. Mina olen programmeerija. Ja ma tean täpselt, millest ma räägin. _________________ It's 5:50 AM. Do you know where your stack pointer is?
Autoriõiguse reformist. EAÜ tegevdirektor Kalev Rattus selgitab Euroopa Parlamendis 05. juulil hääletusel olnud autoriõiguse direktiivi tagamaid.
Spoiler
tsitaat:
Olles lugenud erinevaid seisukohavõtte autoriõiguste direktiivi kohta, mis on mõeldud reformima infoühiskonna autoriõigust, pean vajalikuks selgitada meie liikmetele asja tegelikku olemust.
Pikka aega on autoriõiguse vastased rääkinud, et autoriõigus on rudiment 19. sajandist ja ei sobi kokku tänase infoühiskonnaga. Pärast pikki kõhklusi-kahtlusi asus Brüssel selle teemaga tegelema. Töötati välja eelnõu, millega muuhulgas püütakse reguleerida praegusele ajale omaseid suhteid autoriõiguste ja autoriõigusega kaasnevate õiguste osas Internetis. Seejuures peeti silmas mitut eesmärki. Esiteks luua asjas mingi selgus, kuna Euroopa Liidus (EL) on see teema riigiti väga erinevalt reguleeritud. Teiseks aidata kaasa EL mahajäämuse likvideerimisele sisutootmise/jagamise valdkonnas. Kolmandaks püüda ohjeldada mingilgi määral suurte (peamiselt USA päritolu) sisujagamis-keskkondade laiutamist. Neljandaks tagada autoreile, esitajaile, tootjaile (s.h ka kirjastajaile) õiglasem tasu nende sisu kasutamise eest. Sest olukord, kus suured platvormid teenivad sadu miljardeid ja need, kelle loomingu pealt nad raha teenivad, ei saa sellest suurt midagi, ei tohiks jätkuda. Ehk siis üks eesmärk autorite poolelt vaadates on kaitsta Euroopa kultuuri ja selle mitmekesisust sel teel, et tuua suurtelt sisujagajatelt osa raha tagasi uue Euroopa kultuuri loomiseks.
Mis toimus. Tänu suurte korporatsioonide edukale lobile (ja raha neil selleks leidub ja palju rohkem kui sisu loojatel) loobus enamus (õnneks küll mitte eriti ülekaalukas, ainult 40 hääle erinevusega) Euroopa Parlamendi (EP) saadikuid oma Euroopa autorite huvide kaitsmisest ja asus rahvusvaheliste konglomeraatide taldu lakkuma. Põhjenduseks on ka meie endi EP saadikud toonud muuhulgas sõnavabaduse rikkumise ohu ja selle, et regulatsioon oleks vastupidiselt soovitule ohustanud just väikesi jagamiskeskkondi. See on väga osav demagoogia. Olen lugenud nn vastaspoole levitatud pöördumisi EP liikmetele ja tean kuidas nende ajusid sellise propagandaga pesti. Eriti ilmekas näide on meie rahvusvahelises mõttes olematu tähtsusega Wikimedia seltskond, kes otseselt Wikipedialt saadud juhtnööride järgi Eesti üldsuse ajusid pesi. Kelle huvides? Loomulikult suure Wikipedia huvides.
Huvitav on olnud ka meie ajakirjanduse osa teema avamisel. Tundub, et enamus ajakirjanikest, kes on sel teemal sõna võtnud, ei saa aru, et kuskilt peab tulema ka raha , mida omanikud neile palgana maksavad. Usun, et näiteks hr. Luik ja hr. Linnamäe saavad väga hästi aru, et tasuta asju pole olemas, sest ega muidu pea nende väljaannetes uudise lugemiseks pileti ostma. Ja siin pole mingit vastuolu informatsiooni saamise õiguse kuulutamisega inimõiguseks või kuidas? Miks siis seda ajakirjandusmajanduse põhitõde oma töötajatele ei selgitata? Jääb mulje, et ajakirjanduses töötavadki ainult noorkommunistid, kes tahaksid autoritele kuuluvad õigused võõrandada. Et see on vastuolus ka nende endi vajadustega , seda nad aga ei taipa.
Muidugi ei tähenda eilne hääletus veel seda, et asjaga edasi ei minda. Seda peab tegema niikuinii, sest reaalsed olud vajavad ka seadusandlikku reguleerimist. Aga see on jälle asja edasilükkamine ja iga päev, mil Euroopa bürokraatide veskid seda asja venitavad, tähendavad autoreile kaotatud tasusid ja täidavad ainult suurte failijagamisplatvormide niigi lookas kukruid.
Meie eurosaadikud, peale hr. Tunne Kelami, näitasid ära, kelle poolel nad on. Ja see ei ole mitte autorite pool. Ärge seda siis järgmistel valimistel unustage ja küsige pr. Toomilt, pr. Kallaselt, hr. Paetilt, hr. Padarilt ja hr. Tarandilt, et miks te olete meie, autorite vastu ja miks toetate suurfirmasid. Ja kui näiteks hr. Tarand teile ütleb, et vastupidi, see oli just väikeste toetuseks ja muidu oleksid suured veelgi suuremaks läinud, siis ärge uskuge. Pealegi ei puutu platvormide ja ajakirjanduse jms seltskonna omavaheline kemplemine autoritesse. Teie küsimus olgu – kus on minu osa rahast mida suurfirmad minu teoste pealt teenides oma taskusse ajavad.
Lisan EAÜ liikmetele tutvumiseks ka mõned selle teemaga seotud materjalid:
• EAÜ, EEL ja EFÜ pöördumise Eesti EP saadikute poole;
• Rahvusvahelise Autorite ja Heliloojate Ühingute Konföderatsiooni (CISAC) pressiteate seoses EP hääletusega;
• CISAC-i poolt koostatud analüüsi palju poleemikat tekitanud autoriõiguse direktiivi artiklite 11 ja 13 kohta.
Nad nutavad, et refereering või meem on populaarsem kui reaalne lugu ja selle tegijad ei tohi teenida suures keskkonnas raha.
EAÜ on läbi aegade paistnud silma üsna kiviaegsete mõtetega
... autorite kaitsmisega pole siin ju ilmselgelt midagi pistmist, kaitstakse autoriõiguste valdajaid, kelleks on pea-aegu eranditult just needsamad korporatsioonid, ja nende kommertsambitsioone. Need direktiivid annaks õiguse tulisata süüdimatult kõige pihta, mis neile ei meeldi ja küsimuste küsimuse jätta kellegi teise mureks, mis oleks põhimõtteliselt kommertsõiguste seadmine ülemaks inimeste põhiõigustest tegevus- ja väljenduvabadusele ... _________________
Vana ACTA "sõber" Kalev võiks ameti maha panna, ta ei jaga asjast ei ööd ega mütsi.
Masendav, et nii kitsarinnaliselt asju nähakse.
Vastupidi on - see härra teab isegi une pealt mis kuulsuse ning rikkuse majja toob: "Money talks". (Fig. Money gives one power and influence to help get things done or get one's own way. Don't worry. I have a way of getting things done. Money talks. I can't compete against rich old Mrs. Jones. She'll get her way because money talks.) https://idioms.thefreedictionary.com/money+talks
Peaks kõigile "lohutuseks sobima" väike järgmine muusikapala:
AC/DC - Moneytalks
sa ei või postitada uusi teemasid siia foorumisse sa ei või vastata selle foorumi teemadele sa ei või muuta oma postitusi selles foorumis sa ei või kustutada oma postitusi selles foorumis sa ei või vastata küsitlustele selles foorumis sa ei saa lisada manuseid selles foorumis sa võid manuseid alla laadida selles foorumis
Hinnavaatlus ei vastuta foorumis tehtud postituste eest.