 praegune kellaaeg 02.07.2026 22:29:46
praegune kellaaeg 02.07.2026 22:29:46 |
|
Hinnavaatlus
:: Foorum
:: Uudised
:: Ärifoorumid
:: HV F1 ennustusvõistlus
:: Pangalink
:: Telekavad
:: HV toote otsing
|
|
| autor |
|
Raiku
HV Guru

liitunud: 13.11.2001

|
 18.12.2002 09:56:17
Tom klokkis PeeNelja...
18.12.2002 09:56:17
Tom klokkis PeeNelja... |

|
|
link :: Tomshardware
...ning nagu ise ütleb "...ei olnud antud projekti puhul saavutus mitte kõva klokk vaid stabiilsus sellise kloki juures..."
_________________
Честных психов можно не лечить... |
|
| Kommentaarid: 58 loe/lisa |
Kasutajad arvavad: |
   |
:: |
0 :: |
0 :: |
45 |
|
| tagasi üles |
|
 |
lamp
HV Guru

liitunud: 08.11.2001
|
|
18.12.2002 13:16:30
|
|
|
Njaa aga mis dual ddr400 nad seal räägivad.. kui seal on dual 358 
Lisaks võrdlused imevad vilinal.. oleks taht näha ikka dualddr vs rambus benche sama cpu kiiruse juures..
jne jne.
|
|
| Kommentaarid: 193 loe/lisa |
Kasutajad arvavad: |
|
:: |
1 :: |
1 :: |
169 |
|
| tagasi üles |
|
|
Raiku
HV Guru
liitunud: 13.11.2001
|
|
18.12.2002 14:20:55
|
|
|
| lamp kirjutas: |
Njaa aga mis dual ddr400 nad seal räägivad.. kui seal on dual 358
Lisaks võrdlused imevad vilinal.. oleks taht näha ikka dualddr vs rambus benche sama cpu kiiruse juures..
jne jne. |
Mr/Ms lamp...see oleks vajanud kahte projekti.
_________________
Честных психов можно не лечить... |
|
| Kommentaarid: 58 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
45 |
|
| tagasi üles |
|
|
XYZ
HV Guru

liitunud: 05.11.2001
|
|
18.12.2002 14:40:20
|
|
|
| Rambus... üks test seal ju oli kus rambus konf oli parim (winace test) ja seda ainult tänu rambus mälule.
|
|
| Kommentaarid: 81 loe/lisa |
Kasutajad arvavad: |
|
:: |
3 :: |
12 :: |
56 |
|
| tagasi üles |
|
|
A-Circus.
Kreisi kasutaja

liitunud: 30.10.2002
|
|
18.12.2002 18:35:55
|
|
|
Yhes testis sai 4,1 P4 2,0 Athloni käest ära.
Tase. 
|
|
| Kommentaarid: 50 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
48 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik


liitunud: 19.07.2002
|
|
18.12.2002 21:20:24
|
|
|
| Sittagi ei saanud aru - mis FSB seal siis lopuks kasutusel oli nende DDR'idega?
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
wicked
HV Guru

liitunud: 06.11.2001
|
|
| Kommentaarid: 68 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
1 :: |
63 |
|
| tagasi üles |
|
|
NecroDave
HV kasutaja

liitunud: 16.10.2002
|
|
18.12.2002 21:57:17
|
|
|
Kuda sa sellist looma jahutad  
|
|
| Kommentaarid: 24 loe/lisa |
Kasutajad arvavad: |
|
:: |
1 :: |
0 :: |
16 |
|
| tagasi üles |
|
|
wicked
HV Guru
liitunud: 06.11.2001
|
|
| Kommentaarid: 68 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
1 :: |
63 |
|
| tagasi üles |
|
|
NecroDave
HV kasutaja
liitunud: 16.10.2002
|
|
18.12.2002 22:09:42
|
|
|
No jah  kompressoriga kompressoriga
|
|
| Kommentaarid: 24 loe/lisa |
Kasutajad arvavad: |
|
:: |
1 :: |
0 :: |
16 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
18.12.2002 22:10:04
|
|
|
Tahendab siis malu jooksis 358MHz peal kui yksinda ja 716 kui topelt?
Aga miks nii vahe? Kui oleks 400MHz CPU pannud, siis oleks ju 800MHz
topelt maluga saanud ja seda veel yldsegi ilma klokkimata.
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
Raiku
HV Guru
liitunud: 13.11.2001
|
|
18.12.2002 22:36:49
|
|
|
| LordVader kirjutas: |
Tahendab siis malu jooksis 358MHz peal kui yksinda ja 716 kui topelt?
Aga miks nii vahe? Kui oleks 400MHz CPU pannud, siis oleks ju 800MHz
topelt maluga saanud ja seda veel yldsegi ilma klokkimata. |
No võta siis 3,06 P4 ja pane 400-se siini peal tööle 
_________________
Честных психов можно не лечить... |
|
| Kommentaarid: 58 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
45 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
18.12.2002 22:47:19
|
|
|
| Raiku kirjutas: |
| LordVader kirjutas: |
Tahendab siis malu jooksis 358MHz peal kui yksinda ja 716 kui topelt?
Aga miks nii vahe? Kui oleks 400MHz CPU pannud, siis oleks ju 800MHz
topelt maluga saanud ja seda veel yldsegi ilma klokkimata. |
No võta siis 3,06 P4 ja pane 400-se siini peal tööle |
Mulle tundub vist ka et nii ei saa, aga siit jareldubki et Inteli cpu'd on mitmeid kordi AMD'dest aeglasemad maluga suhtlemise osas.
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
General
HV kasutaja

liitunud: 10.07.2002
|
|
18.12.2002 23:56:45
|
|
|
| LordVader kirjutas: |
| Raiku kirjutas: |
| LordVader kirjutas: |
Tahendab siis malu jooksis 358MHz peal kui yksinda ja 716 kui topelt?
Aga miks nii vahe? Kui oleks 400MHz CPU pannud, siis oleks ju 800MHz
topelt maluga saanud ja seda veel yldsegi ilma klokkimata. |
No võta siis 3,06 P4 ja pane 400-se siini peal tööle |
Mulle tundub vist ka et nii ei saa, aga siit jareldubki et Inteli cpu'd on mitmeid kordi AMD'dest aeglasemad maluga suhtlemise osas. |
vastupidi ikka
|
|
| Kommentaarid: 9 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
9 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
19.12.2002 00:27:48
|
|
|
| General kirjutas: |
| LordVader kirjutas: |
| Raiku kirjutas: |
| LordVader kirjutas: |
Tahendab siis malu jooksis 358MHz peal kui yksinda ja 716 kui topelt?
Aga miks nii vahe? Kui oleks 400MHz CPU pannud, siis oleks ju 800MHz
topelt maluga saanud ja seda veel yldsegi ilma klokkimata. |
No võta siis 3,06 P4 ja pane 400-se siini peal tööle |
Mulle tundub vist ka et nii ei saa, aga siit jareldubki et Inteli cpu'd on mitmeid kordi AMD'dest aeglasemad maluga suhtlemise osas. |
vastupidi ikka |
OK, see Inteli FSB on teema mida vist enam rohkem reklaami huvides sogasemaks ajada ei saagi. AMD'l on nii et FSB'i sead paika ja DDR'i puhul korrutad selle siis kahega et teada saada tegelik CPU ja malu vahelise andmevahetuse sagedus (rising-falling.....).
Malu saab toesti Biosis sellest suuremaks seadistada kui malu seda voimaldab, kuid-kuid see on ainult butafooria, jargi testitud ja praktiliselt
kiirusele ei moika ja ei saagi moigata loogiliselt moeldes, kuna vaiksemast
sagedusest suuremat tehes oleks vagagi absurdne loota infovahetuse kiiruse suurenemist. See malukiiruse seadistus ei muuda asja, ainus
mis loeb on FSB'ist tulenev tegelik kiirus mis DDR'i puhul tuleb
korrutada kahega. Ja dual-channel DDR'i puhul piltlikult veel kahega,
piltlikult kuna voiks ka kahega korrutamat jatta ja oelda et nüüd on 64bit'i
asemel hoopis 128bit.
Ja nüüd kysiksingi siis et mis see tegelik malu ja CPU vaheline kiirus Inteli puhul oli siis?
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
rasm007
Kreisi kasutaja

liitunud: 12.12.2001
|
|
23.12.2002 18:04:02
|
|
|
see ju peris haigelt kiire 
|
|
| Kommentaarid: 15 loe/lisa |
Kasutajad arvavad: |
|
:: |
1 :: |
0 :: |
14 |
|
| tagasi üles |
|
|
stepzter
HV veteran

liitunud: 11.11.2001
|
|
24.12.2002 20:59:46
|
|
|
| LordVader kirjutas: |
Ja nüüd kysiksingi siis et mis see tegelik malu ja CPU vaheline kiirus Inteli puhul oli siis? |
Inteli P4 kasutab northbridgega (mälukontroller, AGP, link southbride' jms) suhtlemiseks 64bitist 4 andmesõna per kellatakt siini. (kui ma õigesti mäletan, siis kasutusel on kaks omavahel 90' nihutatud kella, mõlemal langeva ja tõusva kella serva peal pannakse andmed siinile) Kuni Willamette ja Northwood, kuni 2,4GHz kasutab 100MHz kella, alates 2,26GHz on võimalik saada 133MHz FSB kellaga ja järgmisest aastast peaks tulema 200MHz kellaga. See teeb siis maksimaalseks andmeribalaiuseks esimesel juhul 100'000'000*1/s * 4 * 8*B / 1000^3*B/GB=3,2GB/s. Teisel juhul 4,27 GB/s ja tulev siin oleks 6,4 GB/s.
Palju sealt mäluni on, sõltub juba mälust. PC800 RDRAM on 16bit 400MHz DDR, ehk 1,6 GB/s. Kahe kanaliga 3,2GB/s. PC1066 on ühe kanaliga 2,13GB/s, kahega 4,27GB/s. PC1600 DDR SDRAM on ühe kanaliga 64bit 100MHz DDR, ehk 1,6GB/s, kahega 3,2GB/s. PC2100 on siis 2,13GB/s ja 4,27GB/s. Igaljuhul, üldjuhul, kui õnnestub panna FSB ja mälu sünkroonis jooksma, siis saab mälukontrolleris FIFO queue latentsuse pealt kokku hoida ja protsessor peab infot vähem aega ootama. See ei ole muidugi reegel, teatud juhtudel tasub kiirem mälu kiirus ennast ära, kuna mälu ei suuda läheneda oma täielikule teoreetilisele ribalaiusele, teatud olukordades on kiirem FSB kasulik, kuna mälu ei ole ainukene asi, mis üle FSB jookseb.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
24.12.2002 21:21:42
|
|
|
| stepzter kirjutas: |
esimesel juhul 100'000'000*1/s * 4 * 8*B / 1000^3*B/GB=3,2GB/s. |
Mulle tundub et siin on mingi valearvestus.
Mul tuleb nii:
100'000'000 (FSB) * 2 (DDR'i ylekanne impulsi tousu-languse ajal) *
8 Bait (64bit) = 1600000000 Bait/s = 1.49 GB/s
Peale selle unustasid vist et 1KB=1024baiti mitte 1000baiti
(andestamatu 
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
24.12.2002 22:01:48
|
|
|
| LordVader kirjutas: |
| stepzter kirjutas: |
esimesel juhul 100'000'000*1/s * 4 * 8*B / 1000^3*B/GB=3,2GB/s. |
Mulle tundub et siin on mingi valearvestus.
Mul tuleb nii:
100'000'000 (FSB) * 2 (DDR'i ylekanne impulsi tousu-languse ajal) *
8 Bait (64bit) = 1600000000 Bait/s = 1.49 GB/s
|
Iga kellatakt on 4 ülekannet, kaks DDR ülekannet veerand kellatakti omavahel nihutatud.
| LordVader kirjutas: |
Peale selle unustasid vist et 1KB=1024baiti mitte 1000baiti
(andestamatu :-) |
Ei unustanud: http://physics.nist.gov/cuu/Units/binary.html kB = 1000B KiB = 1024B :)
Tegelikult neid kasutatakse väga ebakonsistentselt ja kuna siinide ribalaius on üldjuhul pandud kirja 1000^x ühikutega, siis ma kasutasin seda, et segadust vältida. Ma isegi kirjutades panin esialgu need suurused kirja ka binaareesliidetega, aga otsustasin, et segaduse vältimiseks on targem need sinna panemata jätta.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
24.12.2002 22:15:12
|
|
|
| stepzter kirjutas: |
Iga kellatakt on 4 ülekannet, kaks DDR ülekannet veerand kellatakti omavahel nihutatud.
|
Huvitav kuidas sellisest asjast :
........ __ .............
....__|....|__.........
.....saab valja voluda neli takti, vist vahe 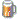
| stepzter kirjutas: |
Ei unustanud: http://physics.nist.gov/cuu/Units/binary.html kB = 1000B KiB = 1024B
Tegelikult neid kasutatakse väga ebakonsistentselt ja kuna siinide ribalaius on üldjuhul pandud kirja 1000^x ühikutega, siis ma kasutasin seda, et segadust vältida. Ma isegi kirjutades panin esialgu need suurused kirja ka binaareesliidetega, aga otsustasin, et segaduse vältimiseks on targem need sinna panemata jätta. |
`kibibit` , hmmm, ikka lolliks lahevad vagisi
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
24.12.2002 23:22:24
|
|
|
| LordVader kirjutas: |
| stepzter kirjutas: |
Iga kellatakt on 4 ülekannet, kaks DDR ülekannet veerand kellatakti omavahel nihutatud.
|
Huvitav kuidas sellisest asjast :
........ __ .............
....__|....|__.........
.....saab valja voluda neli takti, vist vahe (b) :-)
|

|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
25.12.2002 01:25:43
|
|
|
| stepzter kirjutas: |
|
Niisiis nende kahe sageduse summa oleks :
......__..........................
.....|...|.........................
___|...|__.....__.............
..............|...|................
..............|__|...............
Sagedus oleks küll teoreetiliselt 2X, kuid kahtlen kas selline signaali
kasitlus DDR'i puhul kehtib?
Ja peale selle, ytleme et FSB on 100MHz, siis maluga suhtlemise
sagedus tuleks kokku 400MHz. Kuid mis siis juhtub kui mul polegi
masinas 400MHz voimaldavat malu, vaid on hoopis 266MHz, asi laheks
lohki ju.
Peale selle tootab CPU ju nii et on ainult yks sagedus, see mis ongi
CPU core-clock. Selleks et seda korget sagedust synkroniseerida
tunduvalt aeglasema maluga, lisab CPU clock-tsyklitele wait-statesi
(seda teeb cpu, mitte malu), mis lopuks ongi CPU FSB. Muidugi cachiga toimub andmevahetus
ilma wait-statedeta (vana tuntud reklaamipettus jallegi), kuid see
ei muuda asja.
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
25.12.2002 02:31:39
|
|
|
WTF, sa ise ka said aru sellest?
FSB kasutab andmevahetuseks 64 andmetraati, kuhu pannakse vastavalt siis kas 0 pinge või mingid voldid, mida ma peast ei mäleta paari pingetraati millega neid pingeid võrreldakse ja kellatraati, kus jookseb ruutsignaal, mille taktis vaadatakse pingeid andmetraatidel. Loogika lülitusi saab triggerima panna kas pinge tõusu või languse järgi ja kuna korrektset ruutsignaali on raskem kõrge sagedusega tekitada, kui andmesignaali, siis kasutatakse mõlemat äärt ära. P4 FSB on isegi niikaugele läinud, et ühe kellatraadi asemel on kaks tükki, mille peal on omavahel 90' nihutatud ruutsignaalid, millel mõlemate langevad ja tõusvatel äärtel tsekitakse andmetraatide pinget. Seega korrektne oleks öelda, et kellasagedus on 100MHz, andmesagedus on 400MHz.
Ja CPU võtab enda sageduse tegelikult FSB pealt ja korrutab seda, et saada enda sagedust. Ja mäluga sünkroniseerimist sõna otses mõttes ei toimu protsessoris, see toimub mälukontrolleris. Need wait-stated, mida sa eeldad protsessoris olevat on hoopis muu värk. Üks korralik seitsmenda põlvkonna protsessor suudab käskude järjekorda endale sobivalt ümber tõsta mingites piirides ning omab mitu taset vahemälu. P4 puhul on kasutusel 2 tasemeline inclusive vahemälu skeem. See tähendab, et kui tuleb käsk, mis loeb mälust andmeid registrisse, siis kõigepealt pöördutakse L1 ja L2 cachede poole. Kui L1 selle leiab, siis 2 takti pärast on need andmed olemas, ja L2 otsing tühistatakse. Kui L1'st ei leita (L1 miss), siis oodatakse L2 vastust (7 takti), kui seal ka ei ole, siis saadetakse FSB peale päring, et neid andmeid saada. See võtab sõltuvalt protsessori ja mälu kiirusest 100-500 takti. Niikaua, kuni mälust lugemise käsu jaoks andmeid leitud ei ole, ei ole loomulikult võimalik ka täita muid käske, mis seda registrit kasutavad, või sõltuvad käskudest, mis seda regsitrit kasutavad. Et aga protsessor niikaua niisama jalgu ei kõlgutaks (mälust lugemise käske on päris suur protsent tavaliselt), täidetakse neid sõltumatuid käske, mis suudetakse nende hulgast leida, mis mahuvad protsessori ümberjärjestamise aknasse ära. Kui need otsa saavad, siis ei ole protsessoril muud teha, kui niisama istuda, kuni vajalikud andmed leitakse. Sellest tulenevalt saabki kategoriseerida programme põhiliselt bandwithist sõltuvaks, kus protsessoril on suhteliselt palju teha, sel ajal kui mälu taga oodatakse, põhiliselt latentsusest sõltuvaks, kui praktiliselt midagi ei ole niikaua teha, kuni andmed on kätte saadud ja põhiliselt prosa kellast sõltuvaks, kui kas ei vajata palju andmeid, või andmed leitakse kenasti vahemälust ülesse. Reaalsetel programmidel on alati mingi segu nendest kolmest käitumisest.
Protsessorist FSB'd mööda mälukontrolleritesse info saatmine toimub FIFO queue (first in-first out) abil, ehk kui protsessor tahab sinna midagi saata, siis pistab need sinna torusse ja FSB kontroller võtab FSB taktis sealt torust andmeid ja saadab siinile, see eriti latentsust ei lisa, kuna see FIFO töötab CPU sagedusel. Mälukontrolleris endas on asi lihtne, kui mälu ja FSB töötavad ühes taktis, aga kui erinevad taktid on, siis peab kasutama ka FIFO't, mis seal töötab nii palju aeglasemalt, et lisab täiesti arvestatava koguse latentsust mälu päringule.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
General
HV kasutaja
liitunud: 10.07.2002
|
|
25.12.2002 02:37:39
|
|
|
| stepzter kirjutas: |
WTF, sa ise ka said aru sellest?
FSB kasutab andmevahetuseks 64 andmetraati, kuhu pannakse vastavalt siis kas 0 pinge või mingid voldid, mida ma peast ei mäleta paari pingetraati millega neid pingeid võrreldakse ja kellatraati, kus jookseb ruutsignaal, mille taktis vaadatakse pingeid andmetraatidel. Loogika lülitusi saab triggerima panna kas pinge tõusu või languse järgi ja kuna korrektset ruutsignaali on raskem kõrge sagedusega tekitada, kui andmesignaali, siis kasutatakse mõlemat äärt ära. P4 FSB on isegi niikaugele läinud, et ühe kellatraadi asemel on kaks tükki, mille peal on omavahel 90' nihutatud ruutsignaalid, millel mõlemate langevad ja tõusvatel äärtel tsekitakse andmetraatide pinget. Seega korrektne oleks öelda, et kellasagedus on 100MHz, andmesagedus on 400MHz.
Ja CPU võtab enda sageduse tegelikult FSB pealt ja korrutab seda, et saada enda sagedust. Ja mäluga sünkroniseerimist sõna otses mõttes ei toimu protsessoris, see toimub mälukontrolleris. Need wait-stated, mida sa eeldad protsessoris olevat on hoopis muu värk. Üks korralik seitsmenda põlvkonna protsessor suudab käskude järjekorda endale sobivalt ümber tõsta mingites piirides ning omab mitu taset vahemälu. P4 puhul on kasutusel 2 tasemeline inclusive vahemälu skeem. See tähendab, et kui tuleb käsk, mis loeb mälust andmeid registrisse, siis kõigepealt pöördutakse L1 ja L2 cachede poole. Kui L1 selle leiab, siis 2 takti pärast on need andmed olemas, ja L2 otsing tühistatakse. Kui L1'st ei leita (L1 miss), siis oodatakse L2 vastust (7 takti), kui seal ka ei ole, siis saadetakse FSB peale päring, et neid andmeid saada. See võtab sõltuvalt protsessori ja mälu kiirusest 100-500 takti. Niikaua, kuni mälust lugemise käsu jaoks andmeid leitud ei ole, ei ole loomulikult võimalik ka täita muid käske, mis seda registrit kasutavad, või sõltuvad käskudest, mis seda regsitrit kasutavad. Et aga protsessor niikaua niisama jalgu ei kõlgutaks (mälust lugemise käske on päris suur protsent tavaliselt), täidetakse neid sõltumatuid käske, mis suudetakse nende hulgast leida, mis mahuvad protsessori ümberjärjestamise aknasse ära. Kui need otsa saavad, siis ei ole protsessoril muud teha, kui niisama istuda, kuni vajalikud andmed leitakse. Sellest tulenevalt saabki kategoriseerida programme põhiliselt bandwithist sõltuvaks, kus protsessoril on suhteliselt palju teha, sel ajal kui mälu taga oodatakse, põhiliselt latentsusest sõltuvaks, kui praktiliselt midagi ei ole niikaua teha, kuni andmed on kätte saadud ja põhiliselt prosa kellast sõltuvaks, kui kas ei vajata palju andmeid, või andmed leitakse kenasti vahemälust ülesse. Reaalsetel programmidel on alati mingi segu nendest kolmest käitumisest.
Protsessorist FSB'd mööda mälukontrolleritesse info saatmine toimub FIFO queue (first in-first out) abil, ehk kui protsessor tahab sinna midagi saata, siis pistab need sinna torusse ja FSB kontroller võtab FSB taktis sealt torust andmeid ja saadab siinile, see eriti latentsust ei lisa, kuna see FIFO töötab CPU sagedusel. Mälukontrolleris endas on asi lihtne, kui mälu ja FSB töötavad ühes taktis, aga kui erinevad taktid on, siis peab kasutama ka FIFO't, mis seal töötab nii palju aeglasemalt, et lisab täiesti arvestatava koguse latentsust mälu päringule. |
viitsisid ka nii pikka juttu kirjutada? 
|
|
| Kommentaarid: 9 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
9 |
|
| tagasi üles |
|
|
wazaa
HV veteran

liitunud: 13.10.2002
|
|
25.12.2002 02:45:13
|
|
|
| Ai krt athlon sai ikka ysna haledalt aga AMD rulz ikka
|
|
| Kommentaarid: 53 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
5 :: |
40 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
25.12.2002 05:17:32
|
|
|
| stepzter kirjutas: |
Loogika lülitusi saab triggerima panna kas pinge tõusu või languse järgi ja
|
Kuid kas see ikka ddrami puhul on nii et voib olla suvaline tous ja mitte
yksnes 1 ja 0?
| stepzter kirjutas: |
kuna korrektset ruutsignaali on raskem kõrge sagedusega tekitada, kui andmesignaali, siis kasutatakse mõlemat äärt ära. P4 FSB on isegi niikaugele läinud, et ühe kellatraadi asemel on kaks tükki, mille peal on omavahel 90' nihutatud ruutsignaalid, millel mõlemate langevad ja tõusvatel äärtel tsekitakse andmetraatide pinget. Seega korrektne oleks öelda, et kellasagedus on 100MHz, andmesagedus on 400MHz.
|
No tavaliselt on ikka igal pool digielektroonikas nii et kellasagedus oleks
korgem kui andmesagedus et saavutada suuremat stabiilsust.
CPU puhul ju samuti core-clock on tunduvalt kiirem.
| stepzter kirjutas: |
Ja CPU võtab enda sageduse tegelikult FSB pealt ja korrutab seda, et saada enda sagedust.
|
Kas Sa motlesid ka mida vaitsid - tahendab 100Mhz'st tehakse 2GHz,
sellisel juhul tuleks see andmevoog ja prose microkaskude timingud
nagu jumal juhatab.
| stepzter kirjutas: |
Ja mäluga sünkroniseerimist sõna otses mõttes ei toimu protsessoris, see toimub mälukontrolleris.
|
Pole tapselt kursis kuidas P4 on aga voibolla neid wait-state'si voidakse lisada ka malukontrolleris omakorda juurde.
Kuid proses toimub wait-state'de lisamine kohe kindlasti kuna vastasel
juhul poleks naiteks 2GHz core-clocist 100MHz voimalik tehagi.
| stepzter kirjutas: |
Need wait-stated, mida sa eeldad protsessoris olevat on hoopis muu värk. Üks korralik seitsmenda põlvkonna protsessor suudab käskude järjekorda endale sobivalt ümber tõsta mingites piirides ning omab mitu taset vahemälu. ...............................
|
Jah, loomulikult on selleks L1(data/code eraldi), L2 ja ka microkaskude jaoks pipelined, kuid see ei muuda oluliselt asja - cacheid voivad yldse
mitte mingit efecti anda kui info on pidevalt uus ning pipeline ei suuda
hoopiski tasakaalustada core ja malu sageduste erinevust.
| stepzter kirjutas: |
Protsessorist FSB'd mööda mälukontrolleritesse info saatmine toimub FIFO queue (first in-first out) abil, ehk kui protsessor tahab sinna midagi saata, siis pistab need sinna torusse ja FSB kontroller võtab FSB taktis sealt torust andmeid ja saadab siinile, see eriti latentsust ei lisa, kuna see FIFO töötab CPU sagedusel. Mälukontrolleris endas on asi lihtne, kui mälu ja FSB töötavad ühes taktis, aga kui erinevad taktid on, siis peab kasutama ka FIFO't, mis seal töötab nii palju aeglasemalt, et lisab täiesti arvestatava koguse latentsust mälu päringule. |
Ei saa paris hasti aru mida silmas pead, raagid nagu oleks seal ka mingi
cache? Asjad toimuvad pigem ikka vaga konkreetse arvu clock-tsyklite tagant.
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
25.12.2002 06:36:53
|
|
|
| LordVader kirjutas: |
| stepzter kirjutas: |
Loogika lülitusi saab triggerima panna kas pinge tõusu või languse järgi ja
|
Kuid kas see ikka ddrami puhul on nii et voib olla suvaline tous ja mitte
yksnes 1 ja 0?
|
Ei ole päris suvaline tõus, sõltub nendest pingetest, mis vastavatele trigeritele on antud.
| LordVader kirjutas: |
| stepzter kirjutas: |
kuna korrektset ruutsignaali on raskem kõrge sagedusega tekitada, kui andmesignaali, siis kasutatakse mõlemat äärt ära. P4 FSB on isegi niikaugele läinud, et ühe kellatraadi asemel on kaks tükki, mille peal on omavahel 90' nihutatud ruutsignaalid, millel mõlemate langevad ja tõusvatel äärtel tsekitakse andmetraatide pinget. Seega korrektne oleks öelda, et kellasagedus on 100MHz, andmesagedus on 400MHz.
|
No tavaliselt on ikka igal pool digielektroonikas nii et kellasagedus oleks
korgem kui andmesagedus et saavutada suuremat stabiilsust.
CPU puhul ju samuti core-clock on tunduvalt kiirem.
|
Mh? Ma mõtlesin, seda, et andmetraatidel on korrektselt loetavat bitti kergem saavutada kõrgema sagedusega, kui tekitada piisavalt täpset sünkroniseerimis kella.
| LordVader kirjutas: |
| stepzter kirjutas: |
Ja CPU võtab enda sageduse tegelikult FSB pealt ja korrutab seda, et saada enda sagedust.
|
Kas Sa motlesid ka mida vaitsid - tahendab 100Mhz'st tehakse 2GHz,
sellisel juhul tuleks see andmevoog ja prose microkaskude timingud
nagu jumal juhatab.
|
Ei mõelnud, teadsin. Prosades korrutatakse sisendsagedus PLL'de abil läbi, et saada prosa enda sagedus. Ja core sagedus ei oletänu sellele nagu jumal juhatab, et PLL'i sisendite parameetrid peavad väga täpsed olema (st. korraliku lowpass filtriga toide ja madala faasimüraga kell).
| LordVader kirjutas: |
| stepzter kirjutas: |
Ja mäluga sünkroniseerimist sõna otses mõttes ei toimu protsessoris, see toimub mälukontrolleris.
|
Pole tapselt kursis kuidas P4 on aga voibolla neid wait-state'si voidakse lisada ka malukontrolleris omakorda juurde.
Kuid proses toimub wait-state'de lisamine kohe kindlasti kuna vastasel
juhul poleks naiteks 2GHz core-clocist 100MHz voimalik tehagi.
|
See niiöelda wait-state aka. pipeline stall tekib siis, kui FSB FIFO täis saab.
| LordVader kirjutas: |
| stepzter kirjutas: |
Need wait-stated, mida sa eeldad protsessoris olevat on hoopis muu värk. Üks korralik seitsmenda põlvkonna protsessor suudab käskude järjekorda endale sobivalt ümber tõsta mingites piirides ning omab mitu taset vahemälu. ...............................
|
Jah, loomulikult on selleks L1(data/code eraldi), L2 ja ka microkaskude jaoks pipelined, kuid see ei muuda oluliselt asja - cacheid voivad yldse
mitte mingit efecti anda kui info on pidevalt uus ning pipeline ei suuda
hoopiski tasakaalustada core ja malu sageduste erinevust.
|
Sageduste erinevus ei puutu üldse asjasse. Bandwith ja latency on need asjad, mis loevad. Kui programmis on piisavalt paralleelsust ja OOO window piisavalt suur, siis ei ole vahet kas prosale tuleb 8B iga takt, või 8kB iga 1000 takti tagant (1000 kordne sageduste vahe). Kui ei ole piisavalt paralleelsust, siis loeb latentsus, ehk kui iga takt vajatakse mingeid uusi andmeid ja paralleelsust ei ole, siis on iga takt 8B täpselt 1000x kiirem kui 8kB iga 1000 takti tagant.
| LordVader kirjutas: |
| stepzter kirjutas: |
Protsessorist FSB'd mööda mälukontrolleritesse info saatmine toimub FIFO queue (first in-first out) abil, ehk kui protsessor tahab sinna midagi saata, siis pistab need sinna torusse ja FSB kontroller võtab FSB taktis sealt torust andmeid ja saadab siinile, see eriti latentsust ei lisa, kuna see FIFO töötab CPU sagedusel. Mälukontrolleris endas on asi lihtne, kui mälu ja FSB töötavad ühes taktis, aga kui erinevad taktid on, siis peab kasutama ka FIFO't, mis seal töötab nii palju aeglasemalt, et lisab täiesti arvestatava koguse latentsust mälu päringule. |
Ei saa paris hasti aru mida silmas pead, raagid nagu oleks seal ka mingi
cache? Asjad toimuvad pigem ikka vaga konkreetse arvu clock-tsyklite tagant. |
Mitte päris cache, aga mingi asi peab olema, mis andmeid alles hoiab selle aja kuni nad on vastuvõetud ja nad saab välja saata. Puhver, kui see nimi sulle paremini istub.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
25.12.2002 14:46:51
|
|
|
| stepzter kirjutas: |
Mh? Ma mõtlesin, seda, et andmetraatidel on korrektselt loetavat bitti kergem saavutada kõrgema sagedusega, kui tekitada piisavalt täpset sünkroniseerimis kella.
|
Andmete jooksmise sagedus pole tahtis, tahtis on see et selle juhtimiseks
kasutatav sagedus oleks vaga stabiilne s.t. et kellasagedus, mis maha jagatakse, oleks andmete edasikande sagedusest tunduvalt korgem.
| stepzter kirjutas: |
Ei mõelnud, teadsin. Prosades korrutatakse sisendsagedus PLL'de abil läbi, et saada prosa enda sagedus. Ja core sagedus ei oletänu sellele nagu jumal juhatab, et PLL'i sisendite parameetrid peavad väga täpsed olema (st. korraliku lowpass filtriga toide ja madala faasimüraga kell).
|
Sellest vaatamata ei piisa et FSB 100Mhz'st saaks teha naiteks 2GHz coret,
elektroonika lihtsalt ei tootaks nii. Isegi quartz ei oleks sellise asja jaoks
piisavalt tapne.
| stepzter kirjutas: |
See niiöelda wait-state aka. pipeline stall tekib siis, kui FSB FIFO täis saab.
|
Ja see saabki tais juba praktiliselt momentaanselt.
| stepzter kirjutas: |
Sageduste erinevus ei puutu üldse asjasse.
|
Just see puutubki asjasse.
| stepzter kirjutas: |
Bandwith ja latency on need asjad, mis loevad. Kui programmis on piisavalt paralleelsust ja OOO window piisavalt suur
|
No yldiselt prose peab hakkama saama ikka soltumata sellest kuidas
progejal parasjagu tuju oli. Programmidest ei ole cpu'l yldse vaja midagi
teada, see juba progejate mure.
| stepzter kirjutas: |
, siis ei ole vahet kas prosale tuleb 8B iga takt, või 8kB iga 1000 tkti tagant (1000 kordne sageduste vahe).
|
Kysimus ongi selles et cacheid (L1/L2) saavad lihtsalt tais ja kaotavad
oma motte. CPU aga tahab saada igat baiti eraldi, et taita registrit voi
decodeerida lahti microcoodi ja panna see pipelinesse, mis toimib ka
ainult eeldusel et mitut microkasku on voimalik korraga teostada ainult
juhul kui nad on yksteisest soltumatud. Selleks et ei tekiks mingit ummistust, ongi koik asjad paigas kindlate clock-tsyklite tagant (wait-state.)
| stepzter kirjutas: |
Kui ei ole piisavalt paralleelsust, siis loeb latentsus, ehk kui iga takt vajatakse mingeid uusi andmeid ja paralleelsust ei ole, siis on iga takt 8B täpselt 1000x kiirem kui 8kB iga 1000 takti tagant.
|
"takt kiirem"?? Mohkugi ei saa aru. Core-clock ujub voi???
| stepzter kirjutas: |
Mitte päris cache, aga mingi asi peab olema, mis andmeid alles hoiab selle aja kuni nad on vastuvõetud ja nad saab välja saata. Puhver, kui see nimi sulle paremini istub. |
Tore mote, ainult et sellest puhvrist poleks mitte mingit abi kuna ta
saaks praktiliselt kohe tais ja kaotaks motte (kui info liigub cpu poolt mallu) ja kui malust cpu'sse, siis ei joutaks infot nii kiiresti ette anda ja
tekib infokadu.
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
25.12.2002 19:12:45
|
|
|
OEH, sul on suhteliselt kummaline arusaam osadest asajdest, mis IMHO ei ole eriti adekvaatne. Sellegi poolest üritan paaris kohas, kus õnnestub subjektiivsust vältida, vastata.
| LordVader kirjutas: |
| stepzter kirjutas: |
Mh? Ma mõtlesin, seda, et andmetraatidel on korrektselt loetavat bitti kergem saavutada kõrgema sagedusega, kui tekitada piisavalt täpset sünkroniseerimis kella.
|
Andmete jooksmise sagedus pole tahtis, tahtis on see et selle juhtimiseks
kasutatav sagedus oleks vaga stabiilne s.t. et kellasagedus, mis maha jagatakse, oleks andmete edasikande sagedusest tunduvalt korgem.
|
Kas just madalama sagedusega signaali ei olegi võimalik üle trükkplaadi radasid mööda stabiilsemana ja täpsemana kanda. Kõrgemad sagedusega signaalidega hakkavad igasugused induktiivsused ja mahtuvused rohkem rolli mängima. Samuti tekivad signaalipeegeldused.
Mille muu pärast siis kasutatakse just nimelt madalamat sagedust, mitte kõrgemat.
| LordVader kirjutas: |
| stepzter kirjutas: |
Ei mõelnud, teadsin. Prosades korrutatakse sisendsagedus PLL'de abil läbi, et saada prosa enda sagedus. Ja core sagedus ei oletänu sellele nagu jumal juhatab, et PLL'i sisendite parameetrid peavad väga täpsed olema (st. korraliku lowpass filtriga toide ja madala faasimüraga kell).
|
Sellest vaatamata ei piisa et FSB 100Mhz'st saaks teha naiteks 2GHz coret,
elektroonika lihtsalt ei tootaks nii. Isegi quartz ei oleks sellise asja jaoks
piisavalt tapne.
|
Kust siis sinu arvates core enda kella saab? Selle et sinu arust töötada ei saa lükkab minuarust päris kenasti ümber fakt, et see töötab niimoodi.
PC arhitektuuri referencest: The various clocks in the modern PC are created using a single clock generator circuit (on the motherboard) to generate the "main" system clock, and then various clock multiplier or divider circuits to create the other signals.
P4 data sheetist:
Pinide kirjeldusest: VCCA provides isolated power for the internal processor core PLLs.
PLL'de kirjeldusest:
Since these PLLs are analog in nature,
they require quiet power supplies for minimum jitter. Jitter is detrimental to the system; it degrades
external I/O timings as well as internal core timings (i.e., maximum frequency).
Otseselt ei ole seda välja öeldud, et kasutatakse PLL'e, et teha BCLK0 signaalist core clock, sest see peaks igale inimesele kes seda seal loeb ilmselge olema.
| LordVader kirjutas: |
| stepzter kirjutas: |
See niiöelda wait-state aka. pipeline stall tekib siis, kui FSB FIFO täis saab.
|
Ja see saabki tais juba praktiliselt momentaanselt. :-)
|
Tavaliselt lähevad STORE käsud cachesse, kust teatud ruumipuuduse korral selle cache-line'i välja surumisel kirjutatakse see 128B mällu, see FIFO minuteada suudab vähemalt selle 128B endas hoida, et mitte peatada tegevust, kui on vaja kaks cache-line'i swap'ida selle 4 FSB takti jooksul, mis ühe üle kandmiseks kulub, alles siis hakkab probleeme tekkima. Mälu poolt lugemisega ei ole erilisi probleeme niikaua, kuni FSB on mälust kiirem.
| LordVader kirjutas: |
| stepzter kirjutas: |
Sageduste erinevus ei puutu üldse asjasse.
|
Just see puutubki asjasse.
|
Sulle ei tundu pähe mahtuvat, et just nende sageduste erinevustega hakkama saamiseks on süsteemis päris palju igasuguseid puhvreid. Kokkuvõttes loeb see, kas puhver on piisavalt suur, et lühikeste pursetega hakkama saada ja kas allikas, mida puhverdatakse on võimeline välja andma piisava striimi, et puhver tühjaks ei saaks.
| LordVader kirjutas: |
| stepzter kirjutas: |
Bandwith ja latency on need asjad, mis loevad. Kui programmis on piisavalt paralleelsust ja OOO window piisavalt suur
|
No yldiselt prose peab hakkama saama ikka soltumata sellest kuidas
progejal parasjagu tuju oli. Programmidest ei ole cpu'l yldse vaja midagi
teada, see juba progejate mure.
|
Rohkem kompileerijate mure, aga ka heade programmeerijate mure. Lihtsalt ei ole võimalik kõike protsessoris programmeerija eest ära teha. Tänu sellisele suhtumisele sündiski x86, mis on prosaarhitekti õudusunenägu. Kolmandik prosa ressurssidest kulub sellele, et x86 puudujääkidest mööda saada.
| LordVader kirjutas: |
| stepzter kirjutas: |
, siis ei ole vahet kas prosale tuleb 8B iga takt, või 8kB iga 1000 tkti tagant (1000 kordne sageduste vahe).
|
Kysimus ongi selles et cacheid (L1/L2) saavad lihtsalt tais ja kaotavad
oma motte. CPU aga tahab saada igat baiti eraldi, et taita registrit voi
decodeerida lahti microcoodi ja panna see pipelinesse, mis toimib ka
ainult eeldusel et mitut microkasku on voimalik korraga teostada ainult
juhul kui nad on yksteisest soltumatud. Selleks et ei tekiks mingit ummistust, ongi koik asjad paigas kindlate clock-tsyklite tagant (wait-state.)
|
Ma ei saanud midagi aru, mida sa sellega öelda tahad. CPU tahab igat baiti eraldi saada küll, selle jaoks ongi cache, mis laeb andmeid 128B kaupa ja prefetch, mis üritab ettearvatava sammuga lugemisi ette ära teha.
| LordVader kirjutas: |
| stepzter kirjutas: |
Kui ei ole piisavalt paralleelsust, siis loeb latentsus, ehk kui iga takt vajatakse mingeid uusi andmeid ja paralleelsust ei ole, siis on iga takt 8B täpselt 1000x kiirem kui 8kB iga 1000 takti tagant.
|
"takt kiirem"?? Mohkugi ei saa aru. Core-clock ujub voi???
|
Kui kõik instruktsioonid on omavahel sõltuvad ja iga takt loetakse uusi andmeid uuest kohast, siis selline variant, kus FSB on täpselt sünkroonis prosa kellaga ja FSB laius on 8B on 10x kiirem, kui variant, kus FSB on 10x aeglasema kellaga, kui core, ja FSB laius on 80B. Kuna iga kord, kui andmeid vajatakse tuleb oodata ära järgmine FSB takt, et saaks andmeid pärida ja tööga edasi minna. Mul on tunne, et sa eeldad, et selline olukord on reegel, kuigi tegelikult on pigem erand.
| LordVader kirjutas: |
| stepzter kirjutas: |
Mitte päris cache, aga mingi asi peab olema, mis andmeid alles hoiab selle aja kuni nad on vastuvõetud ja nad saab välja saata. Puhver, kui see nimi sulle paremini istub. |
Tore mote, ainult et sellest puhvrist poleks mitte mingit abi kuna ta
saaks praktiliselt kohe tais ja kaotaks motte (kui info liigub cpu poolt mallu) ja kui malust cpu'sse, siis ei joutaks infot nii kiiresti ette anda ja
tekib infokadu. |
Puhver saab praktiliselt kohe täis, kui protsessor on bandwithi poolt piiratud, või kui puhver ei ole piisavalt suur, et puhverdada vähemalt ühte FSB takti. Enamusel juhtudel ei ole protsessorid bandwithi poolt piiratud.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
25.12.2002 20:53:49
|
|
|
| stepzter kirjutas: |
Kas just madalama sagedusega signaali ei olegi võimalik üle trükkplaadi radasid mööda stabiilsemana ja täpsemana kanda. Kõrgemad sagedusega signaalidega hakkavad igasugused induktiivsused ja mahtuvused rohkem rolli mängima. Samuti tekivad signaalipeegeldused.
Mille muu pärast siis kasutatakse just nimelt madalamat sagedust, mitte kõrgemat.
|
Mitte sageduse kiirus pole oluline vaid see kuipalju seda on enne reaalset
kasutust maha jagatud. Mida rohkem kordi maha jagatakse, seda suurem tapsus.
| stepzter kirjutas: |
Kust siis sinu arvates core enda kella saab? Selle et sinu arust töötada ei saa lükkab minuarust päris kenasti ümber fakt, et see töötab niimoodi.
PC arhitektuuri referencest: The various clocks in the modern PC are created using a single clock generator circuit (on the motherboard) to generate the "main" system clock, and then various clock multiplier or divider circuits to create the other signals.
P4 data sheetist:
Pinide kirjeldusest: VCCA provides isolated power for the internal processor core PLLs.
PLL'de kirjeldusest:
Since these PLLs are analog in nature,
they require quiet power supplies for minimum jitter. Jitter is detrimental to the system; it degrades
external I/O timings as well as internal core timings (i.e., maximum frequency).
Otseselt ei ole seda välja öeldud, et kasutatakse PLL'e, et teha BCLK0 signaalist core clock, sest see peaks igale inimesele kes seda seal loeb ilmselge olema.
|
Ma siiski ei peaks neid allikaid piisavalt usaldusvaarseteks, tegemist tundus rohkem populaarteaduslike artiklitega. See et sa saad Bioses
FSB'i kordajaga korrutades katte core-clocki, ei tahenda seda et CPU's
see asi tapselt nii ka toimiks, vaid on ainult moeldud loptarbijale.
Tegelikult muidugi palju loogilisem oleks selline seadistus, et kellageneraatori mahajagamistega Biosis saaksid katte core-clocki ja
wait-statede lisamisega Biosi seadistuses saaksid katte vaiksema FSB'i,
vahendamisega vastavalt suurema FSB'i.
| stepzter kirjutas: |
Tavaliselt lähevad STORE käsud cachesse, kust teatud ruumipuuduse korral selle cache-line'i välja surumisel kirjutatakse see 128B mällu, see FIFO minuteada suudab vähemalt selle 128B endas hoida, et mitte peatada tegevust, kui on vaja kaks cache-line'i swap'ida selle 4 FSB takti jooksul, mis ühe üle kandmiseks kulub, alles siis hakkab probleeme tekkima. Mälu poolt lugemisega ei ole erilisi probleeme niikaua, kuni FSB on mälust kiirem.
................
Sulle ei tundu pähe mahtuvat, et just nende sageduste erinevustega hakkama saamiseks on süsteemis päris palju igasuguseid puhvreid. Kokkuvõttes loeb see, kas puhver on piisavalt suur, et lühikeste pursetega hakkama saada ja kas allikas, mida puhverdatakse on võimeline välja andma piisava striimi, et puhver tühjaks ei saaks.
|
FSB ei saa olla malust ei kiirem ega ka aeglasem kuna asjad peavad olema synkroonis. Mitte FSB ja malu vahel pole probleem vaid hoopis
FSB'i ja core-clocki vahel. Ykski cache ei suuda lopmatuseni kiiremalt
pealejooksvat infot salvestada kui valjund on aeglasem. Ja kiirem valjund ei saa kunagi garanteerida pidevat andmevoogu kui sisend on aeglasem.
| stepzter kirjutas: |
Tänu sellisele suhtumisele sündiski x86, mis on prosaarhitekti õudusunenägu. Kolmandik prosa ressurssidest kulub sellele, et x86 puudujääkidest mööda saada.
|
Olen küll ypriski pohjalikult uurinud Inteli IA-32 386 protected-mode ylesehitust
(linear-aadressi tuletus descriptorite alusel; real-aadressi tuletus pagingu alusel; aadress-level protection; page-level protection; privilege-levels;
segment-descriptor cache; IDT; GDT; LDT; registrid-flagid; io-permission
bitmap; page-extension; virtual-mode;......jne. Uutel cpu'del on seda ainult veidike taiendatud), kuid pole küll sealt leidnud yhtegi puudujaaki, pigem ytleks et raske on tuua vordluseks midagi niivord taiuslikult ja ylimalt detailselt valjatootatud systeemi, iseasi on muidugi see et koigi nende voimaluste optimaalne arakasutus pole joukohane isegi MS suurusele firmale. Inteli sigadusteks pean aga hoopis segmendi-limiidi
sidumist p-modega, descriptor-cachei vagivaldne tyhjendus virtual-modes,
LOADALL instruktsiooni kaotamine ja pagingu sidumine p-modega ning muidugi ka vaga palju Inteli enda poolt levitatud vaarinformatsiooni nendesamade asjade kohta, mis lopuks siiski on avastatud 3rd party isikute poolt.
| stepzter kirjutas: |
Kui kõik instruktsioonid on omavahel sõltuvad ja iga takt loetakse uusi andmeid uuest kohast, siis selline variant, kus FSB on täpselt sünkroonis prosa kellaga ja FSB laius on 8B on 10x kiirem, kui variant, kus FSB on 10x aeglasema kellaga, kui core, ja FSB laius on 80B. Kuna iga kord, kui andmeid vajatakse tuleb oodata ära järgmine FSB takt, et saaks andmeid pärida ja tööga edasi minna. Mul on tunne, et sa eeldad, et selline olukord on reegel, kuigi tegelikult on pigem erand.
|
Mis siis andmed jooksevad core-lock (nait 2GB) taktis voi?
Sellist malugi pole veel loodud. Kunagi ammu, siis olid aga kiirused ka
madalamad, konstrueeriti eksperimendi korras Harvardi ylikoolis 0-wait-statega masin. Ei julge arvatagi mis selline masin tanapaeva kiiruste juures maksta voiks (malu just).
| stepzter kirjutas: |
Puhver saab praktiliselt kohe täis, kui protsessor on bandwithi poolt piiratud, või kui puhver ei ole piisavalt suur, et puhverdada vähemalt ühte FSB takti. Enamusel juhtudel ei ole protsessorid bandwithi poolt piiratud. |
Mis see yks FSB takt paastaks. Aga mida see bandwith yldse siia puutub,
malu on 64bit, 64bit jooksebki malu ja L2 vahel.
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
25.12.2002 21:30:10
|
|
|
| LordVader kirjutas: |
Ma siiski ei peaks neid allikaid piisavalt usaldusvaarseteks, tegemist tundus rohkem populaarteaduslike artiklitega. See et sa saad Bioses
FSB'i kordajaga korrutades katte core-clocki, ei tahenda seda et CPU's
see asi tapselt nii ka toimiks, vaid on ainult moeldud loptarbijale.
Tegelikult muidugi palju loogilisem oleks selline seadistus, et kellageneraatori mahajagamistega Biosis saaksid katte core-clocki ja
wait-statede lisamisega Biosi seadistuses saaksid katte vaiksema FSB'i,
vahendamisega vastavalt suurema FSB'i.
|
Kust kuradi kohast sa neid wait-statesid võtad?
Ja kui sa Inteli poolt emaplaadi valmistajate jaoks kirjutatud datasheeti usaldusväärseks ei pea, mida siis üldse annab pidada. Võta P4 pinide kirjeldus ette ja vaata, mis asjad sinna sisse lähevad. Sagedus genereeritakse mobol ja see läheb läbi BCLK sisendi protsessorisse, mitte mingit muud sisendit ei ole, kust protsessor üldse saaks võtat enda sagedust. Ülejäänud kellasisendid on source synchronous signalingu tarbeks.
| LordVader kirjutas: |
FSB ei saa olla malust ei kiirem ega ka aeglasem kuna asjad peavad olema synkroonis. Mitte FSB ja malu vahel pole probleem vaid hoopis
FSB'i ja core-clocki vahel. Ykski cache ei suuda lopmatuseni kiiremalt
pealejooksvat infot salvestada kui valjund on aeglasem. Ja kiirem valjund ei saa kunagi garanteerida pidevat andmevoogu kui sisend on aeglasem.
|
FSB ei saa mälust kiirem ega aeglasem olla? Kasutaks traditsioonilist võimalikkuse tõestamist sellega, et see on ära tehtud. KT400 jooksutab rahulikult mälu 200MHz peal, samas, kui FSB on 133MHz peal.
Ja see, et cache ei suuda lõpmatuseni puhverdada kiiremat andmevoogu... Loomulikult ei suuda ja ma ei ole seda väitnudki. Kui protsessoril on vaja iga takt mälusse kirjutada, siis ta on piiratud täpselt selle andmemahuga, mis FSB ja mälu suudavad vastu võtta. Asi on selles, et selline käitumine ei ole tavaline. Tavaliselt töötavad programmid korraga mingi kindla hulga andmete sees, mis mahuvad cachesse ära ja cache sisu peab suhteliselt harva vahetama. Isegi striimivate algoritmide puhul on tavaline see, et andmete töötlemine võtab piisavalt palju aega, et bandwithi mitte täis tõmmata.
| LordVader kirjutas: |
| stepzter kirjutas: |
Tänu sellisele suhtumisele sündiski x86, mis on prosaarhitekti õudusunenägu. Kolmandik prosa ressurssidest kulub sellele, et x86 puudujääkidest mööda saada.
|
Olen küll ypriski pohjalikult uurinud Inteli IA-32 386 protected-mode ylesehitust. .......
|
Sa uurisid seda asja softi poolepealt. x86 ISA rakendamine tänapäevastes protsessorites on tõeline õudusunenägu. Peab mütsi maha võtma Inteli ja AMD inseneride ees, et nad on suutnud nii kavalaid meetodeid v'lja mõelda, et ISA puudujääkidest mööda saada. Võrdle kasvõi mõne RISC prosa nagu alpha pipeline skeemi x86 prosade omaga. Alphal on instruktsiooni dekodeerimine 3x-4x lühem. Samuti ei tule kasuks 7 reaalselt kasutatavat GPR registrit, mis piiravad instruktsioonide paralleliseerimist ja tekitavad väga suure hulga tarbetuid LOAD/STORE instruktsioone.
| LordVader kirjutas: |
Mis siis andmed jooksevad core-lock (nait 2GB) taktis voi?
Sellist malugi pole veel loodud. Kunagi ammu, siis olid aga kiirused ka
madalamad, konstrueeriti eksperimendi korras Harvardi ylikoolis 0-wait-statega masin. Ei julge arvatagi mis selline masin tanapaeva kiiruste juures maksta voiks (malu just).
|
See oli teoreetiline näide, et seletada minu pointi. Sulle lihtsalt ei tundu kohale jõudvat üldine bandwithi ja latentsuse läbi programmi töö kirjelduse mõte.
| LordVader kirjutas: |
| stepzter kirjutas: |
Puhver saab praktiliselt kohe täis, kui protsessor on bandwithi poolt piiratud, või kui puhver ei ole piisavalt suur, et puhverdada vähemalt ühte FSB takti. Enamusel juhtudel ei ole protsessorid bandwithi poolt piiratud. |
Mis see yks FSB takt paastaks. Aga mida see bandwith yldse siia puutub,
malu on 64bit, 64bit jooksebki malu ja L2 vahel. |
Mälu ja L2 vahel jookseb 64bit korda FSB andmesagedus baiti sekundis, L2 ja core vahel jookseb 256bit korda core sagedus baiti sekundis. Need ongi vastavad bandwithid, ehk kui palju andmeid ajaühiku jooksul üle kanda suudetakse. See, kui palju koormatakse FSB'd sõltub L2 hitratest, ehk mitu protsenti päringutest leidub l2 caches. Tavaliselt on se kuskil 96-98%. Seega see suur sageduse vahe ei loe midagi.
Üldiselt selle diskussiooni jaoks peaks üritama mingi vahekokkuvõtte teha, mida üldse kumbki väita üritab. Mul on tunne, et see teema hakkab laiali valguma ja üks räägib aiast teine aiaaugust. Seda aga mitte täna, vähemalt minu poolt mitte.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
LordVader
Lõuapoolik
liitunud: 19.07.2002
|
|
25.12.2002 22:12:06
|
|
|
| stepzter kirjutas: |
Kust kuradi kohast sa neid wait-statesid võtad?
Ja kui sa Inteli poolt emaplaadi valmistajate jaoks kirjutatud datasheeti usaldusväärseks ei pea, mida siis üldse annab pidada. Võta P4 pinide kirjeldus ette ja vaata, mis asjad sinna sisse lähevad. Sagedus genereeritakse mobol ja see läheb läbi BCLK sisendi protsessorisse, mitte mingit muud sisendit ei ole, kust protsessor üldse saaks võtat enda sagedust. Ülejäänud kellasisendid on source synchronous signalingu tarbeks.
|
OK, minu viga, emaplaadil genereeritakse aga sellegipoolest aeglasemast sagedusest suurema genereerimine on lihtsalt reeglite vastane kui tahta jaada mingigi stabiilsuse tasemele.
| stepzter kirjutas: |
FSB ei saa mälust kiirem ega aeglasem olla? Kasutaks traditsioonilist võimalikkuse tõestamist sellega, et see on ära tehtud. KT400 jooksutab rahulikult mälu 200MHz peal, samas, kui FSB on 133MHz peal.
|
No kui FSB on 133MHz ja kasutad 400MHz malu, siis malu jookseb tegelikult 266MHz peal nagu FSB'ki (133x2 ddr'i puhul)
| stepzter kirjutas: |
Ja see, et cache ei suuda lõpmatuseni puhverdada kiiremat andmevoogu... Loomulikult ei suuda ja ma ei ole seda väitnudki. Kui protsessoril on vaja iga takt mälusse kirjutada, siis ta on piiratud täpselt selle andmemahuga, mis FSB ja mälu suudavad vastu võtta. Asi on selles, et selline käitumine ei ole tavaline. Tavaliselt töötavad programmid korraga mingi kindla hulga andmete sees, mis mahuvad cachesse ära ja cache sisu peab suhteliselt harva vahetama. Isegi striimivate algoritmide puhul on tavaline see, et andmete töötlemine võtab piisavalt palju aega, et bandwithi mitte täis tõmmata.
|
Jah, selleks cache'i kasutataksegi, kuid ainult selleks et ideaalsetes tingimustes saavutada suuremat kiirust. Kuid selle alusel systeemi planeerimine oleks krahh kuna peab arvestama ikka koikide voimalustega.
| stepzter kirjutas: |
Võrdle kasvõi mõne RISC prosa nagu alpha pipeline skeemi x86 prosade omaga. Alphal on instruktsiooni dekodeerimine 3x-4x lühem.
|
Jah, muidugi on lyhem ja kiirem kuna kasud on lyhemad, vahemate variatsioonidega ja yhepikkused. Mulle aga kui rohkem softist huvitatule
sympatiseerivad CISC prosed kuna meeldib palju ja rikkalik valik instruktsioone.
| stepzter kirjutas: |
Üldiselt selle diskussiooni jaoks peaks üritama mingi vahekokkuvõtte teha, mida üldse kumbki väita üritab. Mul on tunne, et see teema hakkab laiali valguma ja üks räägib aiast teine aiaaugust. Seda aga mitte täna, vähemalt minu poolt mitte. |
Toenaoliselt me toepoolest raagime erinevatest asjadest, aga ykstapuha,
ega see polegi mingi eluline kysimus, lihtsalt pyhade ajal hakkas igav.
Tanan et viitsisid minuga diskuteerida ja
HAID JOULUPYHI KA KOIGILE!
|
|
| Kommentaarid: 28 loe/lisa |
Kasutajad arvavad: |
|
:: |
6 :: |
6 :: |
11 |
|
| tagasi üles |
|
|
stepzter
HV veteran
liitunud: 11.11.2001
|
|
25.12.2002 22:29:52
|
|
|
Kiire vastus enne kui kruvikeerajad kruvisi keerama hakkavad.
| LordVader kirjutas: |
No kui FSB on 133MHz ja kasutad 400MHz malu, siis malu jookseb tegelikult 266MHz peal nagu FSB'ki (133x2 ddr'i puhul)
|
Mälu jookseb 400MHz peal ikka. Lihtsalt mälust ei ole prosal võimalik rohkem välja lugeda, kui FSB läbi laseb, DMA asjad nagu IDE kontroller, AGP jne saavad seda ülejäänud mahtu ära kasutada. Ainult prosa kohapealt oleks isegi parem, kui mälu jooksekski täpselt sama kiirusega naga FSB, kuna siis saab täpselt ühes taktis panna käima. Muidu kulub veel aega selle peale, et ühes taktis sisse tulevad andmed teises taktis välja lasta.
| LordVader kirjutas: |
Jah, selleks cache'i kasutataksegi, kuid ainult selleks et ideaalsetes tingimustes saavutada suuremat kiirust. Kuid selle alusel systeemi planeerimine oleks krahh kuna peab arvestama ikka koikide voimalustega.
|
Üldiselt jägitakse arvutite projekteerimisel reeglit, et tavaline juhtum oleks kiire ja ebatavaline talutav. Ja peaks ütlema, et see on minuarust suhteliselt hästi välja tulnud. Vähemalt P4 on minu arust oluliselt suurem saavutus protsessori arhitektuuri seisukohalt kui nüüd jaanuaris välja tulev uus Alpha. Et 20 aastat vanast CISC arhitektuurist on selline kiirus välja pigistatud on lihtsalt imetlusväärne. Jääb lihtsalt üle mõelda, mis oleks siis, kui kogu see vaev ei oleks rakendatud anaalseks mandlite eemaldamiseks.
| LordVader kirjutas: |
| stepzter kirjutas: |
Võrdle kasvõi mõne RISC prosa nagu alpha pipeline skeemi x86 prosade omaga. Alphal on instruktsiooni dekodeerimine 3x-4x lühem.
|
Jah, muidugi on lyhem ja kiirem kuna kasud on lyhemad, vahemate variatsioonidega ja yhepikkused. Mulle aga kui rohkem softist huvitatule
sympatiseerivad CISC prosed kuna meeldib palju ja rikkalik valik instruktsioone.
|
Tarkvara inimest tegelikult ei peaks ISA üldse puudutama. Selle jaoks on kompilaatorid. x86 CISC'st muideks kasutatakse praktikas ainult väheseid suhteliselt RISC'i sarnaseid käske ja need sisemiselt dekodeeritekase praktiliselt täiesti RISC'ks.
[quote="LordVader"]
| stepzter kirjutas: |
Toenaoliselt me toepoolest raagime erinevatest asjadest, aga ykstapuha,
ega see polegi mingi eluline kysimus, lihtsalt pyhade ajal hakkas igav.
Tanan et viitsisid minuga diskuteerida ja
HAID JOULUPYHI KA KOIGILE! |
Eks mul oli ka igav. Suht nadi on haigena kodus istuda pühade ajal. Oligi paras ajaviide. Enda väiteid üle kontrollides sai nii mõndagi palju täpsemalt teada, kui enne teadis. Nii, aga nüüd screwdriveri kallale (b) :)
PS: meeldiv, et siin foorumil nii teadlike inimesi ka on.
|
|
| Kommentaarid: 26 loe/lisa |
Kasutajad arvavad: |
|
:: |
0 :: |
0 :: |
26 |
|
| tagasi üles |
|
|
Winterwind
One

liitunud: 19.05.2002
|
|
25.12.2002 23:04:59
|
|
|
mhmh
ehk l6petaks edaspidi poole lehekylje quotemise? 
kes viitsib iga kord sama jura lugeda v6i siis pool lehekylge teksti allapoole kerida?
|
|
| Kommentaarid: 1009 loe/lisa |
Kasutajad arvavad: |
|
:: |
3 :: |
1 :: |
728 |
|
| tagasi üles |
|
|
|
| lisa lemmikuks |
|
 |
sa ei või postitada uusi teemasid siia foorumisse
sa ei või vastata selle foorumi teemadele
sa ei või muuta oma postitusi selles foorumis
sa ei või kustutada oma postitusi selles foorumis
sa ei või vastata küsitlustele selles foorumis
sa ei saa lisada manuseid selles foorumis
sa võid manuseid alla laadida selles foorumis
|
|
Hinnavaatlus ei vastuta foorumis tehtud postituste eest.
|




